Stock to Flow colpisce il Mac: come l'AI si è mangiata la tua RAM
A marzo 2025 Apple ha lanciato il Mac Studio M3 Ultra permettendo di configurarlo fino a 512GB di memoria unificata. Era un prodotto vetrina. Quasi nessuno aveva bisogno di tutta quella RAM in un desktop. Il punto era che l’opzione esistesse e che Apple potesse onorarla.
Quattordici mesi dopo, a maggio 2026, Apple ha silenziosamente tolto l’opzione 256GB dalla stessa macchina. Due mesi prima aveva tolto l’opzione 512GB. La configurazione massima che un cliente può ordinare oggi, in qualsiasi parte del mondo, è 96GB. Lo screenshot qui sotto viene dallo store Apple degli Emirati; gli store USA, UK e Italia mostrano lo stesso tetto.
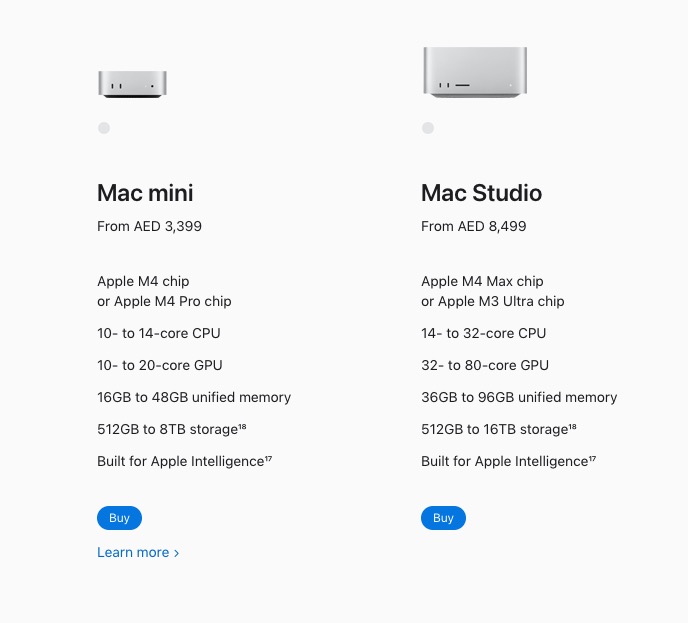
È l’azienda con più potere di prezzo della tecnologia, sulla sua workstation di punta, che taglia la memoria massima di circa l’ottanta per cento in quattordici mesi. I tagli non sono una decisione di design e non sono una decisione di marketing. Sono l’ammissione che persino Apple non riesce a procurarsi tutta la DRAM che vorrebbe. Questo articolo parla del perché.
In breve: l’allenamento dei modelli di AI ha riscritto il mercato della memoria più velocemente di quanto il mercato della memoria possa riscrivere sé stesso. Il meccanismo si capisce meglio attraverso un vecchio strumento dell’economia delle materie prime, lo stock-to-flow, che dice esattamente quali tipi di commodity riescono ad assorbire un’ondata di domanda e quali no. La DRAM non ce la fa. La stretta che vedi nelle SKU dei Mac è la punta avanzata di una discrepanza strutturale che non si risolverà prima del 2027, forse più tardi.
L’articolo passa attraverso lo strumento concettuale, l’ondata di domanda da AI, i colli di bottiglia fisici della produzione, la geopolitica che adesso si sovrappone, le leve algoritmiche disponibili al lato consumer e i numeri pratici sulle macchine che potresti pensare di comprare.
Cos’è davvero lo stock-to-flow
Il modello viene dall’economia delle commodity ed è stato portato a un pubblico più ampio da The Bitcoin Standard. Confronta due grandezze semplici. Lo stock è la quantità di una commodity già in esistenza. Il flow è il ritmo di nuova produzione annua. Il rapporto fra i due dice come si comporta un mercato sotto stress.
Una commodity con stock-to-flow alto ha decenni di inventario esistente rispetto all’estrazione o produzione annua. L’oro è il caso da manuale. Sono state estratte in totale circa 220 000 tonnellate d’oro nella storia, e il mondo ne aggiunge circa 3 500 tonnellate l’anno. Il rapporto è intorno a sessanta. Anche se l’estrazione raddoppiasse domani, l’offerta totale non si muoverebbe quasi, perché lo stock fuori terra esistente domina. È per questo che il prezzo dell’oro risponde alle oscillazioni di domanda molto più che a quelle di offerta; il lato offerta è essenzialmente fissato su qualsiasi orizzonte umano.
Una commodity con stock-to-flow basso è l’opposto. Gli inventari sono brevi rispetto alla produzione annua. Il petrolio, il rame e gran parte delle commodity industriali si comportano così. Il mercato si chiude attraverso il flow, il che significa che domanda e offerta devono essere quasi in equilibrio in ogni momento perché non c’è un cuscinetto su cui attingere. Quando la domanda balza, non puoi svuotare l’inventario perché non c’è. I prezzi salgono, e restano alti finché la produzione non raggiunge la domanda. Il tempo di sollievo è fissato dalla velocità con cui la produzione può scalare.
La DRAM è uno degli esempi più puliti di commodity a basso stock-to-flow nell’industria moderna. Il mercato della memoria gira sul just-in-time. I tre produttori rimasti, SK Hynix, Samsung e Micron, tengono volutamente bassi gli inventari di prodotto finito perché hanno vissuto abbastanza cicli di boom-bust da sapere che tenere magazzino durante un calo dei prezzi distrugge i loro margini. Quindi, quando arriva un’ondata di domanda imprevista, non c’è nessun magazzino da svuotare e il mondo deve aspettare che escano nuovi wafer da fabbriche la cui capacità è già allocata.
Lo stock-to-flow è utile anche perché ti dice, prima di costruire un modello dettagliato, se una stretta si misurerà in mesi o in anni. Se una commodity a basso stock-to-flow viene colpita da un’ondata di domanda più grande del ramp produttivo annuo, la stretta dura finché o l’ondata di domanda si rompe o nuova capacità produttiva entra in funzione. Una fabbrica di DRAM richiede tre anni per essere costruita e un altro anno per andare a regime. Se l’ondata di domanda è più grande di quanto il flow esistente possa assorbire, l’aritmetica ti dà subito la risposta, e la risposta è anni.
È esattamente la situazione in cui siamo.
La DRAM è la commodity da manuale a basso S2F
Per capire perché la stretta attuale è diversa per intensità ma non per natura, aiuta ricordare la storia recente. La DRAM ha attraversato cicli di boom e bust ripetutamente dagli anni Novanta. Il build-out del cloud del 2017-2018 ha prodotto un picco serio. Il boom pandemico di PC e server del 2020-2022 ne ha prodotto un altro. Ogni ciclo ha seguito lo stesso schema: la domanda è scattata, i prezzi sono saliti per dodici-diciotto mesi, i produttori hanno alzato i prezzi a contratto e annunciato nuovi capex, e poi il ciclo si è rotto quando o la domanda si è raffreddata o la nuova produzione ha raggiunto il livello. L’impronta digitale di una commodity a basso stock-to-flow in un mercato vincolato dal flow.
Due caratteristiche strutturali del mercato DRAM amplificano ogni ciclo. La prima è l’oligopolio a tre. Non ci sono nuovi entranti di rilievo perché i costi di capitale sono troppo alti e le curve di apprendimento tecnologico sono troppo ripide. La cinese CXMT è l’unico nuovo giocatore credibile e resta più o meno un nodo di processo indietro. La seconda è che la DRAM è interscambiabile dal lato compratore. Operatori cloud, OEM server, OEM PC, OEM mobile e produttori di dispositivi consumer fanno tutti offerte sullo stesso bacino di wafer. Quando un segmento esplode, soffoca gli altri. Il mercato è un unico pozzo con più bevitori.
Sopra a tutto questo si sovrappone un fatto nuovo dal 2023, che è il motivo per cui il ciclo attuale sembra diverso dai precedenti. L’allenamento dei modelli AI ha introdotto un tipo di domanda che è insieme qualitativamente nuovo e quantitativamente enorme.
L’ondata di domanda da AI
Vale la pena leggere ad alta voce i numeri, perché sono più grandi di quanto la gente pensi.
Nel primo trimestre 2026, i prezzi spot della DRAM erano su di circa il 90 per cento trimestre su trimestre, secondo TrendForce. I prezzi a contratto della DRAM server, per lo stesso trimestre, sono stati rilanciati del 60-70 per cento, con Samsung e SK Hynix che a quanto si dice hanno presentato quei numeri a Microsoft e Google in formula prendere-o-lasciare. La HBM3e, la memoria ad alta banda che siede accanto alle GPU Nvidia, è salita di un ulteriore 20 per cento sopra ai prezzi 2025 già elevati, e la HBM4 spot girava a circa 500 dollari per stack. Gli analisti dell’industria stimano ora che la HBM consumi circa il 20 per cento di tutta la capacità di wafer DRAM, secondo TrendForce, partendo da una quota a singola cifra due anni prima. La produzione 2026 di HBM dei produttori era già completamente pre-prenotata entro fine 2025.
Da dove viene la domanda? Quasi tutta dal capex per l’allenamento AI degli hyperscaler. Microsoft, Meta, Google, Amazon, Oracle e una manciata di player più piccoli si sono impegnati a spendere centinaia di miliardi di dollari in infrastruttura AI tra 2025 e 2027. Gran parte di quel denaro finisce a Nvidia, e ogni acceleratore Nvidia spedisce con molta HBM a bordo. Un H100 porta 80GB. Un H200 ne porta 141. Un B200 ne porta 192. Un rack Blackwell spedisce con diversi terabyte di HBM distribuiti sui suoi acceleratori. Moltiplica per i milioni di acceleratori in fase di dispiegamento e la domanda sulla supply chain della memoria è senza precedenti.
Quello che rende questo ciclo diverso dai precedenti non è solo la scala ma l’inelasticità. Gli hyperscaler non possono sostituire facilmente. Non possono eseguire un training di frontiera con meno memoria; sia la dimensione del modello sia lo stato dell’ottimizzatore scalano con la rete, e ti serve abbastanza memoria per farceli stare. Quindi quando la HBM diventa cara, pagano. Il problema dei price-taker è quello di qualcun altro, cioè il tuo, e quel qualcun altro si rivela essere il mercato DRAM consumer.
Perché la HBM ruba dalla tua macchina
Il meccanismo per cui la domanda AI di HBM si traduce in Apple che taglia le configurazioni del Mac Studio non è ovvio finché non viene esplicitato. Passa per due colli di bottiglia condivisi.
Il primo è la capacità di fabbricazione dei wafer. La HBM è costruita su normali wafer DRAM. I chip che vengono impilati in un modulo HBM sono prodotti sulle stesse linee che fanno la DDR5 per i server, la LPDDR5 per i telefoni e la memoria unificata che sta accanto ad Apple Silicon. Quando SK Hynix o Samsung riassegna capacità dalla DDR5 alla HBM, quella capacità sparisce dal lato consumer del mercato. Non c’è una fabbrica HBM separata; c’è una fabbrica che produce un certo tipo di wafer, e quella viene allocata fra i prodotti a valle.
Il secondo è il packaging avanzato. I moduli HBM non sono chip singoli. Sono pile di die DRAM collegati da through-silicon via e impacchettati su un interposer accanto alla GPU o all’acceleratore. Il processo CoWoS di TSMC è la tecnologia di interposer dominante, e la capacità CoWoS è stata il vincolo stringente sulla produzione di HBM per due anni. Costruire nuove linee CoWoS è a sua volta un progetto pluriennale. Finché quella capacità non esiste, il resto della supply chain non può spedire più HBM, per quanti wafer tu produca.
L’effetto combinato è che wafer e slot di packaging che avrebbero fatto DDR5 o LPDDR5 per laptop, desktop, server e telefoni stanno invece facendo HBM per i data center. L’offerta di memoria consumer si stringe. I prezzi della memoria consumer salgono. Gli OEM PC, che comprano memoria a contratto, vedono i costi più alti trasferirsi a valle e o se li mangiano, o alzano i prezzi, o, come Apple, riducono semplicemente le configurazioni massime offerte per non doversi impegnare a destinare il budget di memoria limitato a SKU vetrina che quasi nessuno compra.
Il tetto di 96GB sul Mac Studio è la contabilità fisica di questo trade-off, resa visibile.
Cosa non riesci a far girare su 128GB
La conseguenza più dura della stretta è cosa significa per ciò che i consumatori possono effettivamente fare su una workstation oggi. La capacità AI è diventata il nuovo uso dominante per i desktop con molta memoria, e la domanda rilevante non è più «posso montare video in 8K», è «quali modelli riesco a far girare in locale».
Per ancorare la domanda, guarda la risposta che Nvidia dà di sé stessa. DGX Spark, rilasciato all’inizio del 2026, è quello che Nvidia spedisce come suo «supercomputer AI personale». È costruito attorno al superchip GB10 Grace Blackwell, eroga circa 1 PFLOPS di prestazione AI a FP4, sta in un cubo di 150 millimetri e costa qualche migliaio di dollari. La sua specifica di copertina sono i 128GB di memoria unificata coerente, condivisa fra il lato CPU e il lato GPU così che modelli molto grandi possano essere caricati senza il sovraccarico di spostare pesi attraverso un confine PCIe.
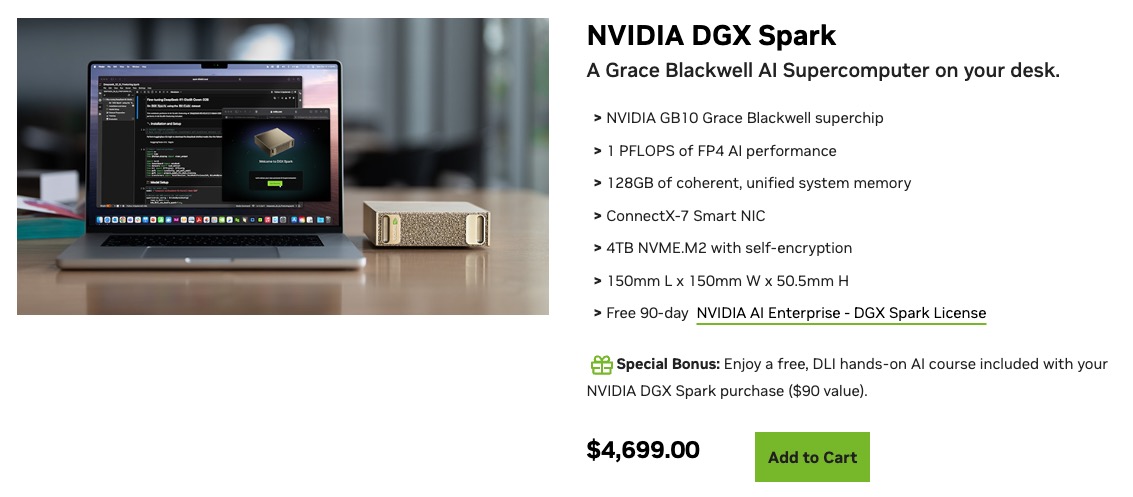
Questo numero, 128GB, non è arbitrario. È la scommessa pubblicata di Nvidia su quale sia il tetto consumer per l’AI nell’attuale ambiente di offerta. Il mercato delle workstation AI personali ha ora due ancore: 96GB su un Mac Studio M3 Ultra e 128GB su uno Spark. Tutto il resto è cloud multi-GPU o una workstation assemblata a mano con più GPU discrete e la relativa complessità software.
Quindi cosa ci sta dentro, e cosa no, sulla frontiera open-weight a giugno 2026?
| Modello | Parametri totali | Parametri attivi | Dimensione approssimativa a 4-bit | Sta in 96GB | Sta in 128GB |
|---|---|---|---|---|---|
| Gemma 4 26B (MoE) | 26B | 3,8B attivi | ≈ 13 GB | sì | sì |
| Gemma 4 31B (denso) | 31B | densi | ≈ 16 GB | sì | sì |
| Qwen3-Coder-Next 80B (MoE) | 80B | 3B attivi | ≈ 40 GB | sì | sì |
| Qwen3.5 (122B MoE) | 122B | 10B attivi | ≈ 61 GB | sì | sì |
| Qwen3 235B-A22B (MoE) | 235B | 22B attivi | ≈ 118 GB | no | a malapena (nessun headroom per il contesto) |
| GLM 5.2 (MoE) | ≈ 744B | 40B attivi | ≈ 372 GB | no | no |
| DeepSeek V4 (MoE, apr 2026) | ≈ 1,6 T | ≈ 49B attivi | ≈ 800 GB | no | no |
La lettura è scomoda ma precisa. 96GB ti permettono di far girare la frontiera open dell’anno scorso, la classe dei 70 miliardi di parametri. 128GB la estendono fino alla frontiera open di metà gamma di oggi, la classe MoE dai 100 ai 122 miliardi di parametri. Nessuna delle due ti permette di far girare la vera frontiera open di oggi su una macchina sola. Qwen3 235B-A22B sta a malapena su 128GB a 4-bit e solo senza vero margine per il contesto. GLM 5.2, attorno ai tre quarti di trilione di parametri, e DeepSeek V4, intorno agli 1,6 trilioni, sono fuori portata per qualsiasi macchina consumer; farli girare a qualsiasi precisione utilizzabile significa server multi-GPU o cloud.
Questa è la traduzione lato consumatore della stretta. Il taglio della SKU Apple non è solo una scocciatura per i power user. Inchioda il mercato consumer all’incirca una generazione indietro rispetto a quello che è oggi possibile sul lato open-weight dell’industria. Uno sviluppatore a Dubai o a Milano può far girare in locale la frontiera dell’anno scorso. Non può far girare quella di quest’anno. La stretta ha un costo in competenza.
Perché la produzione non riesce a scalare
La domanda naturale a questo punto è perché tutto questo non si risolva costruendo più capacità. La domanda è enorme. I prezzi sono saliti di ordini di grandezza in alcuni segmenti. I produttori sono altamente profittevoli. Perché non scalano?
La risposta onesta sono tre colli di bottiglia fisici, ognuno misurato in anni anziché trimestri.
Il primo è la fabbricazione in sé. Una fabbrica DRAM di frontiera costa circa 20 miliardi di dollari e richiede due-tre anni dalla posa della prima pietra al primo wafer. Dopo il primo wafer ne servono altri dodici-diciotto per portare le rese al punto in cui la fabbrica contribuisce in modo significativo all’offerta. Una fabbrica che comincia oggi non muove il mercato prima del 2028.
Il secondo è la litografia EUV. Le fabbriche di frontiera girano tutte su scanner extreme-ultraviolet di ASML, che è l’unica azienda al mondo che li costruisce. L’obiettivo pubblicato da ASML è di circa 60 sistemi EUV standard all’anno, in salita verso gli 80 nel 2027. L’EUV ad alta NA, lo strumento di nuova generazione che servirà ai nodi di processo più aggressivi, esce in pochi esemplari all’anno data l’attuale maturità produttiva. I tempi di consegna per nuovi ordini si misurano in anni. Ogni produttore di memoria gareggia per le stesse macchine di ogni fonderia di logica. La capacità non arriva più velocemente di quanto ASML possa costruire i suoi strumenti.
Il terzo è il packaging avanzato, specificamente il CoWoS per la HBM. Le linee CoWoS di TSMC e la capacità analoga di Amkor e dei player coreani girano a piena potenza e vengono espanse il più rapidamente possibile, ma il packaging avanzato è difficile, e la catena di fornitura degli strumenti per farlo è essa stessa vincolata. La roadmap CoWoS di TSMC mostra aggiunte utili di capacità nel 2026 e 2027 ma, di nuovo, su un orizzonte pluriennale.
Sovrapposto a questi tre c’è lo sforzo statunitense di riportare la produzione in patria, reale e serio ma lento. Il CHIPS Act ha stanziato 52 miliardi di dollari in sussidi. La lista dei progetti di fabbrica dal 2022 è impressionante sui nomi: Intel Ohio, TSMC Arizona (Fab 21 e Fab 22 in programma), Samsung Taylor, Micron Boise e Micron Clay (il mega-sito previsto in New York), SK Hynix West Lafayette per il packaging, più vari progetti minori. Ma la cronologia è dura. Intel Ohio ha slittato più volte. TSMC Arizona produce logica di frontiera, non memoria. Samsung Taylor è logica. Le uniche fabbriche di memoria USA degne di nota sono Micron Boise (primo wafer non prima del 2027) e Micron Clay (slittata più volte e ora data per primo wafer non prima del 2030, con il pieno regime del mega-sito che si estende negli anni Trenta e Quaranta). I player coreani della memoria non stanno spostando capacità di wafer in patria in quantità significativa. SK Hynix West Lafayette è packaging avanzato, non wafer DRAM.
Lettura onesta: entro la fine degli anni Venti gli Stati Uniti avranno spostato in patria una capacità di logica significativa e un po’ di capacità di memoria, ma durante la stretta vera e propria le fab USA non sono il sollievo. Capitale che potrebbe espandere fabbriche coreane esistenti viene dirottato verso siti USA greenfield più lenti per ragioni strategiche. Il programma di reshoring sta, in questo senso, in parte causando la durata della stretta, non risolvendola.
La geopolitica in cui la stretta è ora incastonata
Una stretta da commodity guidata dalla domanda diventa un tipo di problema diverso quando la commodity è anche una risorsa strategica. Entro il 2026 i mercati DRAM e HBM sono chiaramente in quella categoria, e tre fili di politica si stanno intrecciando fra loro.
Il primo è il regime statunitense di controlli sulle esportazioni verso la Cina, che si è inasprito a tappe dal 2022. Gli Stati Uniti limitano la vendita di acceleratori AI di frontiera alla Cina e hanno progressivamente stretto le regole su cosa di HBM può essere spedito dove. La restrizione specifica sulla HBM è arrivata con la regola del Bureau of Industry and Security del 2 dicembre 2024, che ha di fatto escluso HBM2E e successive dal prodotto destinato alla Cina. A giugno 2026 Taiwan si è mossa per allargare i propri controlli, estendendo restrizioni in precedenza focalizzate su Huawei a tutti i clienti cinesi di componenti AI fabbricati a Taiwan. È un’escalation significativa perché il CoWoS, il collo di bottiglia del packaging HBM, vive a TSMC. Una regola taiwanese più completa stringe ulteriormente dove gli acceleratori che portano HBM possono atterrare legalmente.
Il secondo è la vulnerabilità strategica della supply chain in sé. La HBM del mondo viene fatta da due aziende coreane e impacchettata da una taiwanese. Qualsiasi crisi nello Stretto di Taiwan che interrompesse le operazioni di TSMC bloccherebbe in poche settimane le spedizioni mondiali di acceleratori AI. Qualsiasi provocazione nordcoreana che minacciasse la cintura coreana della memoria farebbe lo stesso per la HBM. Non esiste una seconda fonte plausibile sul tipo di orizzonte temporale che conta in una crisi. Questa concentrazione è essa stessa un argomento di stock-to-flow: il lato produzione è concentrato geograficamente oltre che economicamente, e quella concentrazione è un rischio di coda che i mercati non stanno prezzando.
Il terzo è la risposta politica interna negli Stati Uniti, dove la cornice della supremazia AI ha preso piede su entrambi gli schieramenti. Il senatore Bernie Sanders ha presentato un disegno di legge che propone il 50 per cento di proprietà pubblica delle aziende AI statunitensi, con la quota federale a finanziare un dividendo annuo di mille dollari per cittadino. Il vicepresidente JD Vance ha dichiarato, in interviste di inizio mese, che all’amministrazione Trump «piace l’idea» che gli Stati Uniti prendano partecipazioni azionarie in ogni grande azienda AI statunitense, preferendo quella che Vance chiama «pre-distribuzione» all’approccio a dividendo diretto di Sanders. Che una qualunque proposta del genere passi o no, il fatto che due politici che rappresentano estremi opposti dello spettro convergano sulla proprietà governativa USA delle aziende AI è di per sé informazione. È il tipo di riflesso politico che emerge solo quando un’industria è diventata così importante e così strategicamente vincolata che i mercati non vengono più considerati l’allocatore giusto.
Puoi leggere questi tre fili come storie separate o leggerli insieme. Letti insieme, sono un resoconto da manuale di cosa succede quando una commodity a basso stock-to-flow incontra una cornice di risorsa strategica durante un’ondata di domanda. I controlli sulle esportazioni si stratificano sopra alla produzione vincolata. La concentrazione geografica moltiplica il rischio di coda. La politica interna allunga la mano verso le partecipazioni azionarie perché il solo segnale di prezzo non sta più facendo il lavoro che i governi vorrebbero.
La stretta, in altre parole, non è solo un evento economico. È un evento che le maggiori potenze hanno deciso di trattare come strategico. Quella decisione sopravvivrà al picco dei prezzi.
Quanto durerà
La domanda naturale è quando tutto questo si risolverà e la risposta naturale è «più tardi rispetto alle previsioni ottimistiche». Faccio i conti.
Sul lato offerta, la capacità di wafer DRAM di base cresce all’incirca del 5-7 per cento anno su anno tramite normale espansione. La capacità HBM cresce più rapidamente, forse del 50-80 per cento anno su anno per tutto il 2026, ma da una base piccola, e quella crescita sta a sua volta mangiando capacità di wafer che sarebbe altrimenti finita in prodotti non-HBM. Su gran parte delle previsioni degli analisti, la crescita netta della nuova offerta di DRAM consumer nel 2026 è molto vicina a zero. SK Hynix ha segnalato che l’offerta resterà vincolata per tutto il secondo semestre 2026. Nessuna delle nuove fabbriche USA è nel quadro del sollievo. La prima data plausibile per una nuova offerta significativa, sommando Micron Boise più le espansioni coreane più aggiunte modeste di CoWoS, è la fine del 2027.
Sul lato domanda, il capex AI degli hyperscaler proiettato continua a crescere fino al 2027 in tutte le previsioni di consenso che riesco a trovare. Non c’è alcuna decelerazione osservabile negli ordini per i cluster di training. I principali laboratori di modelli continuano ad annunciare nuove generazioni su cicli di sei-nove mesi. Qualsiasi singolo hyperscaler potrebbe sbattere le palpebre, ma la dinamica è collettiva: nessuno vuole essere il primo a tagliare, perché ciascuno di loro è in competizione per un bacino finito di talento AI di frontiera e un vantaggio finito sui dati di training. Quindi l’ondata di domanda è improbabile che si rompa da sola prima della fine del 2027 o del 2028.
Restano due contro-leve lato domanda che vale la pena prendere sul serio.
La prima è la quantizzazione. La quantizzazione è ciò che permette ai modelli grandi di entrare in meno memoria rappresentando ogni parametro con meno bit. La precisione di training di default è FP16, a due byte per parametro. INT8 la dimezza senza quasi costi di qualità. INT4, lo standard attuale per l’inferenza locale, la dimezza di nuovo, e un modello da 70 miliardi di parametri che peserebbe 140 gigabyte in FP16 pesa circa 35 gigabyte a INT4. La ricerca ha ora spinto sotto i 4 bit, con schemi a 1,58 bit come BitNet b1.58 che producono modelli utilizzabili. Ogni dimezzamento della larghezza in bit dimezza all’incirca la memoria richiesta per gli stessi pesi, ma i guadagni si appiattiscono quando ci si avvicina al pavimento di un bit per parametro, oltre il quale il modello diventa una calcolatrice. L’attuale consenso colloca il pavimento per inferenza di alta qualità da qualche parte fra 1,58 e 2 bit.
Dal 2022, la quantizzazione ha comprato all’incirca un fattore otto di efficienza di memoria per inferenza rispetto a FP16. È una risposta lato domanda reale ed è l’unico motivo per cui l’hardware consumer è ancora in gioco. Ma è un cuscinetto one-shot. Una volta arrivati a due bit, non c’è quasi più nulla da comprimere. Le dimensioni dei modelli di frontiera intanto continuano a crescere di 5-10 volte per generazione. L’aritmetica favorisce il lato modello sul lato quantizzazione su qualsiasi orizzonte più lungo di un paio di generazioni.
La seconda contro-leva è architetturale. I modelli mixture-of-experts come Qwen3.5 122B-A10B e DeepSeek V4 usano un grande numero totale di parametri ma instradano ogni token attraverso solo una piccola frazione di quei parametri. Dal punto di vista dell’inferenza, questo offre un modo per mantenere la capacità di frontiera riducendo la memoria di lavoro necessaria per richiesta. I modelli MoE sono comunque pesanti in memoria perché tutti i parametri devono essere caricati da qualche parte, ma riducono il lato calcolo dell’inferenza di un ordine di grandezza, il che li rende più pratici su hardware di fascia più bassa. La combinazione di architettura MoE e quantizzazione aggressiva è all’incirca la migliore risposta tecnica che il lato domanda ha allo squeeze, e la comunità open-weight sta spingendo forte in entrambe le direzioni.
Combina le due leve e la lettura pratica è questa. I consumatori continueranno ad ottenere più capacità per ogni gigabyte di memoria fino al 2027 e al 2028, forse di un altro fattore due o quattro. Le dimensioni dei modelli di frontiera supereranno comunque quel ritmo. La stretta sull’hardware consumer dura quindi in qualche forma fino alla fine del decennio, ma il suo carattere cambia: passa da «non riesci a far girare nulla» a «non riesci a far girare la frontiera». Che è, grossomodo, dove siamo oggi.
Riflessione finale
Lo stock-to-flow è una lente utile perché ti dice, prima di costruire un modello dettagliato, chi paga e quanto tempo ci vuole perché il conto arrivi.
Nella stretta DRAM del 2025-2027, chi paga è ormai chiaro. Pagano gli hyperscaler, con compressione di margine sul loro capex AI, ma hanno il cash flow per assorbirlo. I produttori di memoria guadagnano, con espansione di margine che si è già vista nelle trimestrali di SK Hynix e Samsung. I consumatori pagano la parte più sorprendente del conto, perché il mercato consumer è il compratore residuo della capacità di wafer, e il compratore residuo paga sempre per primo quando l’offerta si stringe. Apple che taglia la RAM massima del Mac Studio da 512GB a 96GB in quattordici mesi è una manifestazione specifica. Prezzi più alti per PC e telefoni, tetti di memoria più bassi sulle workstation e un ritardo di circa una generazione su quello che si può far girare in locale sono le manifestazioni più ampie.
Quando finisce? L’aritmetica dà una risposta più chiara dei titoli di giornale. La produzione non riesce a scalare in modo significativo prima della fine del 2027. La quantizzazione compra qualche altro gigabyte per dollaro ma si avvicina al suo pavimento fisico. Quindi la stretta finisce solo quando l’ondata di domanda AI si rompe, il che sulle traiettorie attuali non avviene prima del 2028 e potrebbe richiedere di più. I governi stanno già cominciando a comportarsi come se ci volesse molto più tempo, ed è per questo che gli argomenti di nazionalizzazione e le escalation sui controlli alle esportazioni stanno spuntando in posti in cui non sarebbero spuntati due anni fa.
Vale la pena fare un passo indietro e notare quanto questo quadro faccia rima con il punto più profondo de il saggio su slug e Bitcoin. In quel pezzo l’argomento era che le commodity ad alto stock-to-flow fanno una buona moneta, perché il loro valore è stabile rispetto agli shock di domanda e i loro produttori non possono barare. Il mercato DRAM è l’altro capo dello stesso asse. È una commodity a basso stock-to-flow il cui valore oscilla violentemente al ritmo della domanda, i cui produttori cavalcano quelle oscillazioni fino a profitti enormi e perdite altrettanto grandi, e i cui consumatori le cavalcano come una tassa. I due saggi argomentano la stessa cornice dai due capi. Lo stock-to-flow alto protegge chi tiene. Lo stock-to-flow basso fa la fattura ai consumatori. Il Mac che avresti potuto comprare con 256GB l’anno scorso e che non puoi comprare quest’anno è la fattura che arriva.
C’è una piccola ironia con cui chiudere. L’ondata che si è mangiata la RAM del tuo laptop è la stessa che, fra due o tre anni, produrrà gli strumenti AI che ti sarebbe piaciuto farci girare. Il trucco è arrivare oltre la stretta abbastanza a lungo perché quegli strumenti arrivino e la stretta finisca. La risposta onesta del mercato, a giugno 2026, è: compra tutta la memoria che puoi permetterti adesso, perché l’anno prossimo pagherai di più per meno.
Riferimenti
- Apple no longer offers M3 Ultra Mac Studio with original highest RAM configuration. 9to5Mac, 5 marzo 2026. https://9to5mac.com/2026/03/05/apple-no-longer-offers-m3-ultra-mac-studio-with-original-highest-ram-configuration/
- Mac Studio 512GB RAM Option Disappears Amid Global DRAM Shortage. MacRumors, 5 marzo 2026. https://www.macrumors.com/2026/03/05/mac-studio-no-512gb-ram-upgrade/
- Apple Cuts More Mac Studio and Mac Mini RAM Options as Memory Shortage Worsens. MacRumors, 5 maggio 2026. https://www.macrumors.com/2026/05/05/apple-mac-studio-mac-mini-ram-cuts/
- Apple quietly axes 128GB Mac Studio amid supply constraints and local AI frenzy. Tom’s Hardware, maggio 2026. https://www.tomshardware.com/desktops/apple-quietly-axes-128gb-mac-studio-amid-supply-constraints-and-local-ai-frenzy-highest-memory-capacity-reduced-to-96gb-two-months-after-discontinuation-of-512gb-model
- Samsung, SK Reportedly Hike Server DRAM Prices 60-70%; Google, Microsoft in the Queue. TrendForce, 6 gennaio 2026. https://www.trendforce.com/news/2026/01/06/news-samsung-sk-reportedly-hike-server-dram-prices-60-70-google-microsoft-in-the-queue/
- Samsung, SK hynix Reportedly Plan ~20% HBM3E Price Hike for 2026. TrendForce, 24 dicembre 2025. https://www.trendforce.com/news/2025/12/24/news-samsung-sk-hynix-reportedly-plan-20-hbm3e-price-hike-for-2026-as-nvidia-h200-asic-demand-rises/
- DRAM and NAND prices jump as Samsung, SK Hynix and Micron tighten supply. Astute Group, 2026. https://www.astutegroup.com/news/memory-shortages/dram-and-nand-prices-jump-as-samsung-sk-hynix-and-micron-tighten-supply/
- Pagina prodotto NVIDIA DGX Spark (GB10 Grace Blackwell, 1 PFLOPS FP4, 128GB di memoria unificata coerente). NVIDIA Marketplace, 2026. https://marketplace.nvidia.com/
- NVIDIA DGX Spark In-Depth Review: A New Standard for Local AI Inference. LMSYS Org, 13 ottobre 2025. https://www.lmsys.org/blog/2025-10-13-nvidia-dgx-spark/
- Open-Source LLMs Landscape: Qwen, Llama, DeepSeek, Kimi. Codersera, maggio 2026. https://codersera.com/blog/open-source-llms-landscape-2026/
- A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026. Sebastian Raschka, 2026. https://magazine.sebastianraschka.com/p/a-dream-of-spring-for-open-weight
- Bernie Sanders files bill proposing 50% public ownership of US AI firms; VP Vance says Trump supports giving the American people a stake in AI companies, prefers ‘pre-distribution’ over giving away cash. Tom’s Hardware, giugno 2026. https://www.tomshardware.com/tech-industry/artificial-intelligence/bernie-sanders-files-bill-proposing-50-percent-public-ownership-of-us-ai-firms-and-giving-out-usd1-000-dividends-vp-vance-says-trump-supports-giving-the-american-people-a-stake-in-ai-companies-prefers-pre-distribution-over-giving-away-cash
- Taiwan Reportedly Mulls Tighter AI Chip Export Rules on China Beyond Huawei. TrendForce, 10 giugno 2026. https://www.trendforce.com/news/2026/06/10/news-taiwan-reportedly-mulls-tighter-ai-chip-export-rules-on-china-beyond-huawei-raising-risks-for-server-makers-like-foxconn/
- Saifedean Ammous (2018). The Bitcoin Standard: The Decentralized Alternative to Central Banking. Wiley. Fonte per la cornice stock-to-flow applicata alle commodity monetarie.
- U.S. CHIPS and Science Act, comunicati del Department of Commerce sui sussidi alle fabbriche e sulle cronologie dei beneficiari: Intel Ohio, TSMC Arizona, Samsung Taylor, Micron Boise e Clay, SK Hynix West Lafayette. https://www.commerce.gov/