Stock to Flow Hits the Mac: How AI Ate Your RAM
In March 2025, Apple launched the Mac Studio M3 Ultra and let you configure it with up to 512GB of unified memory. It was a halo product. Almost nobody needed that much RAM in a desktop. The point was that the option existed and that Apple could fill it.
Fourteen months later, in May 2026, Apple quietly removed the 256GB option from the same machine. Two months before that they had removed the 512GB option. The maximum configuration any customer can order today, anywhere in the world, is 96GB. The screenshot below is from the UAE Apple store; the US, UK, and Italian stores show the same ceiling.
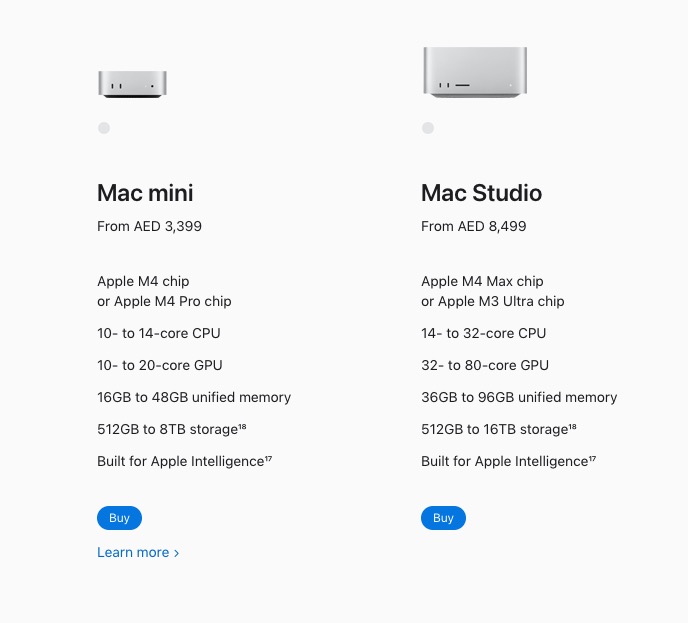
That is the most pricing-powerful company in technology, on its flagship workstation, cutting maximum memory by roughly 80 percent in fourteen months. The cuts are not a design decision and they are not a marketing decision. They are an admission that even Apple cannot get the DRAM it wants. This article is about why.
The short version: AI training has rewritten the memory market faster than the memory market can rewrite itself. The mechanism is best understood through an old economic framework, stock-to-flow, that says exactly which kinds of commodities can absorb a demand shock and which cannot. DRAM cannot. The squeeze you are seeing in Mac SKUs is the leading edge of a structural mismatch that will not resolve before 2027, possibly later.
This piece walks through the framework, the AI demand wave, the physical bottlenecks in production, the geopolitics now layered on top, the algorithmic counter-leverage available to consumers, and what the practical numbers actually look like on the hardware you might think of buying.
What stock-to-flow actually is
The framework comes from commodity economics and was given a wider audience by The Bitcoin Standard. It compares two simple quantities. Stock is the amount of a commodity already in existence. Flow is the rate of new production per year. The ratio of stock to flow tells you how a market behaves under stress.
A high stock-to-flow commodity has decades of existing inventory compared to annual mining or production. Gold is the textbook case. Roughly 220,000 tonnes of gold have ever been mined, and the world adds about 3,500 tonnes a year. The ratio is around sixty. Even if mining doubled tomorrow, total supply would barely move, because the existing above-ground stock dominates. This is why gold prices respond to demand swings far more than to supply swings; the supply side is essentially fixed on any human time horizon.
A low stock-to-flow commodity is the opposite. Inventories are short relative to annual production. Oil, copper, and most industrial commodities behave this way. The market clears through flow, which means that supply and demand have to be close to balance at all times because there is no buffer to draw on. When demand jumps, you cannot raid the inventory because there isn’t much of one. Prices spike, and they stay spiked until production catches up. The time to relief is set by how fast production can ramp.
DRAM is one of the cleanest examples of a low stock-to-flow commodity in modern industry. The memory market runs on just-in-time inventory. The three remaining producers, SK Hynix, Samsung, and Micron, deliberately keep finished-goods inventory thin because they have lived through enough boom-bust cycles to know that holding inventory through a price decline destroys their margins. So when an unexpected demand wave hits, there is no warehouse to empty, and the world has to wait for new wafers to come out of fabs whose capacity is already accounted for.
Stock-to-flow is also useful because it tells you, before you build a detailed model, whether a squeeze will be measured in months or in years. If a low stock-to-flow commodity gets hit by a demand shock larger than the annual production ramp, the squeeze lasts until either the demand wave breaks or new production capacity comes online. New DRAM fabs take three years to build and another year to ramp. If the demand wave is bigger than what existing flow can absorb, the math gives you the answer immediately, and the answer is years.
This is exactly the situation we are in.
DRAM is the textbook low-S2F commodity
To see why the current squeeze is different in degree but not in kind, it helps to remember the recent history. DRAM has run through boom-and-bust cycles repeatedly since the 1990s. The cloud build-out of 2017–2018 produced a serious spike. The pandemic-era PC and server boom of 2020–2022 produced another. Each cycle followed the same template: demand surged, prices climbed for twelve to eighteen months, producers raised contract prices and announced new fab capex, and then the cycle broke when either demand cooled or new production caught up. The fingerprint of a low stock-to-flow commodity in a flow-constrained market.
Two structural features of the DRAM market amplify each cycle. The first is the three-player oligopoly. There are no significant new entrants because the capital costs are too high and the technology learning curves are too steep. China’s CXMT is the only credible newer player and remains roughly a full process node behind. The second is that DRAM is interchangeable on the buy side. Cloud operators, server OEMs, PC OEMs, mobile OEMs, and consumer device makers all bid into the same pool of wafers. When one segment surges, it crowds out the others. The market is a single pool with multiple drinkers.
Layered on top of all that is one new fact since 2023, which is the reason the current cycle looks different from previous ones. AI training has introduced a kind of demand that is both qualitatively new and quantitatively enormous.
The AI demand shock
The numbers are worth saying out loud because they are larger than most people think.
In Q1 2026, DRAM spot prices were up roughly 90 percent quarter over quarter, according to TrendForce. Server DRAM contract pricing for the same quarter was hiked 60 to 70 percent, with Samsung and SK Hynix reportedly pitching Microsoft and Google those numbers as take-it-or-leave-it. HBM3e, the high-bandwidth memory that sits next to Nvidia GPUs, was up a further 20 percent on top of already-elevated 2025 pricing, and HBM4 spot was running at roughly $500 per stack. Industry analysts now estimate that HBM is consuming around 20 percent of all DRAM wafer capacity, per TrendForce, up from a single-digit share two years earlier. The producers’ 2026 HBM production was fully pre-booked by the end of 2025.
Where is the demand coming from? Almost entirely from AI training capex at the hyperscalers. Microsoft, Meta, Google, Amazon, Oracle, and a handful of smaller players have committed to spending in the high hundreds of billions of dollars on AI infrastructure during 2025–2027. Most of that money ends up at Nvidia, and every Nvidia accelerator ships with a lot of HBM attached. An H100 carries 80GB. An H200 carries 141GB. A B200 carries 192GB. A Blackwell rack ships with several terabytes of HBM across its accelerators. Multiply by the millions of accelerators being deployed and the demand on the memory supply chain is unprecedented.
What makes this different from previous cycles is not just the scale but the inelasticity. The hyperscalers cannot easily substitute. They cannot run a frontier-scale training job with less memory; the model size and the optimizer state both scale with the network, and you need enough memory to fit it. So when HBM gets expensive, they pay. The price-takers’ problem is somebody else’s, namely yours, and that somebody else turns out to be the consumer DRAM market.
Why HBM steals from your laptop
The mechanism by which AI demand for HBM translates into Apple cutting Mac Studio configurations is not obvious until you see it spelled out. It runs through two shared bottlenecks.
The first is wafer fab capacity. HBM is built on standard DRAM wafers. The chips that get stacked into an HBM module are produced on the same lines that make DDR5 for servers, LPDDR5 for phones, and the unified memory that sits next to Apple Silicon. When SK Hynix or Samsung reassigns capacity from DDR5 to HBM, that capacity is gone from the consumer side of the market. There is no separate HBM fab; there is one fab, making one kind of wafer, that gets allocated between products downstream of fabrication.
The second is advanced packaging. HBM modules are not single chips. They are stacks of DRAM dies bonded together with through-silicon vias and packaged onto an interposer alongside the GPU or accelerator. TSMC’s CoWoS process is the dominant interposer technology, and CoWoS capacity has been the binding constraint on HBM production for two years. Building more CoWoS lines is its own multi-year project. Until that capacity exists, the rest of the supply chain cannot ship more HBM no matter how much wafer you produce.
The combined effect is that wafers and packaging slots that would have made DDR5 or LPDDR5 for laptops, desktops, servers, and phones are instead making HBM for data centers. Consumer memory supply tightens. Consumer memory prices rise. PC OEMs, who buy memory on contract, see the higher costs flow through and either eat them, raise prices, or, like Apple, simply reduce the maximum configurations they offer so that they do not have to commit to allocating their constrained memory budget to halo SKUs that almost nobody buys.
The 96GB ceiling on the Mac Studio is the physical accounting of this trade-off, made visible.
What you actually cannot run on 128GB
The harder consequence of the squeeze is what it means for what consumers can actually do on a workstation today. AI capability has become the dominant new use for high-memory desktop computers, and the relevant question is no longer “can I edit 8K video,” it is “what models can I run locally.”
To anchor that question, look at Nvidia’s own answer. DGX Spark, released in early 2026, is what Nvidia ships as its “personal AI supercomputer.” It is built around the GB10 Grace Blackwell superchip, delivers about 1 PFLOPS of FP4 AI performance, fits in a 150-millimeter cube, and costs in the low single thousands of dollars. Its headline specification is 128GB of coherent unified memory, shared between the CPU side and the GPU side so that very large models can be loaded without the overhead of moving weights across a PCIe boundary.
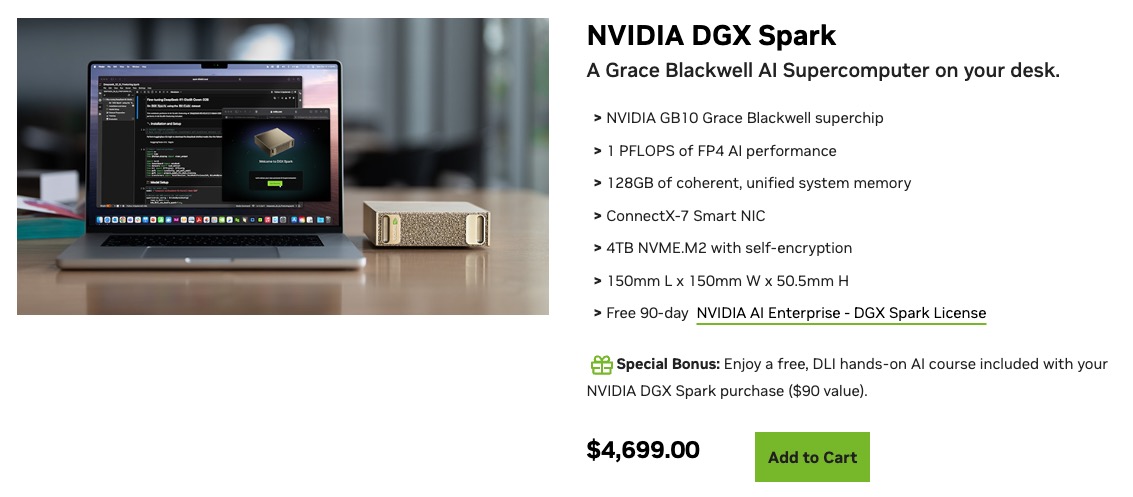
This number, 128GB, is not arbitrary. It is Nvidia’s published bet on what the consumer AI ceiling looks like in the current supply environment. The market for personal AI workstations now has two anchors: 96GB on a Mac Studio M3 Ultra and 128GB on a Spark. Everything else is multi-GPU cloud or a hand-built workstation with multiple discrete GPUs and the associated software complexity.
So what fits, and what does not, at the open-weight frontier as of June 2026?
| Model | Total params | Active params | Approximate size at 4-bit | Fits in 96GB | Fits in 128GB |
|---|---|---|---|---|---|
| Gemma 4 26B (MoE) | 26B | 3.8B active | ≈ 13 GB | yes | yes |
| Gemma 4 31B (dense) | 31B | dense | ≈ 16 GB | yes | yes |
| Qwen3-Coder-Next 80B (MoE) | 80B | 3B active | ≈ 40 GB | yes | yes |
| Qwen3.5 (122B MoE) | 122B | 10B active | ≈ 61 GB | yes | yes |
| Qwen3 235B-A22B (MoE) | 235B | 22B active | ≈ 118 GB | no | barely (no headroom for context) |
| GLM 5.2 (MoE) | ≈ 744B | 40B active | ≈ 372 GB | no | no |
| DeepSeek V4 (MoE, Apr 2026) | ≈ 1.6 T | ≈ 49B active | ≈ 800 GB | no | no |
The reading is uncomfortable but precise. 96GB lets you run last year’s open frontier, the 70-billion-parameter class. 128GB extends that to today’s mid-tier open frontier, the 100-to-122-billion-parameter MoE class. Neither lets you run today’s actual frontier open weights on a single machine. Qwen3 235B-A22B barely fits at 4-bit on 128GB and only without meaningful context headroom. GLM 5.2, at roughly three-quarters of a trillion parameters, and DeepSeek V4 at roughly 1.6 trillion, are out of reach for any consumer-tier box; running them at any usable precision means multi-GPU servers or the cloud.
This is the consumer-side translation of the squeeze. The Apple SKU cut is not just an inconvenience for power users. It locks the consumer market roughly a generation behind what is currently possible on the open-weight side of the industry. A developer in Dubai or Milan today can run last year’s frontier locally. They cannot run this year’s. The squeeze has a competence cost.
Why production cannot ramp
The natural follow-up question is why all of this is not simply solved by building more capacity. Demand is enormous. Pricing is up by orders of magnitude in some segments. The producers are highly profitable. Why does it not ramp?
The honest answer is three physical bottlenecks, each measured in years rather than quarters.
The first is fabrication itself. A leading-edge DRAM fab costs roughly $20 billion to build and takes two to three years from groundbreaking to first wafer. After first wafer it takes another twelve to eighteen months to ramp yields to the point where the fab is contributing meaningfully to supply. Any fab that begins construction today does not move the market until 2028 at the earliest.
The second is EUV lithography. The leading-edge fabs all run on extreme-ultraviolet scanners from ASML, which is the only company in the world that builds them. ASML’s published target is roughly 60 standard EUV systems per year, climbing to about 80 in 2027. High-NA EUV, the next-generation tool that the most aggressive process nodes need, ships in only a few units per year given current production maturity. Lead times for new orders are measured in years. Every memory producer is competing for the same machines as every logic foundry. Capacity does not arrive any faster than ASML can build the tools.
The third is advanced packaging, specifically CoWoS for HBM. CoWoS lines at TSMC and the analogous capacity at Amkor and at the Korean players are running flat out and being expanded as fast as the equipment chain allows, but advanced packaging is hard, and the equipment supply chain for it is itself constrained. TSMC’s CoWoS roadmap shows useful capacity additions through 2026 and 2027 but, again, on a multi-year timeline.
Layered on these three is the United States reshoring effort, which is real and serious but slow. The CHIPS Act allocated $52 billion in subsidies. The fab construction list since 2022 is impressive in name: Intel Ohio, TSMC Arizona (Fab 21 and the planned Fab 22), Samsung Taylor, Micron Boise and Micron Clay (the planned New York mega-site), SK Hynix West Lafayette for packaging, plus various smaller projects. But the relevant timeline is sobering. Intel Ohio has slipped repeatedly. TSMC Arizona is producing on leading-edge logic, not memory. Samsung Taylor is logic. The only US memory fabs of note are Micron Boise (first wafer 2027 at earliest) and Micron Clay (which has slipped repeatedly and is now guided to first wafer no sooner than 2030, with the mega-site full ramp running into the 2030s and 2040s). The Korean memory players are not moving wafer capacity onshore in meaningful quantity. SK Hynix West Lafayette is advanced packaging, not DRAM wafers.
The honest read: by the late 2020s the US will have moved meaningful logic capacity onshore and a little memory capacity, but during the squeeze itself, US fabs are not the relief. Capital that could be expanding existing Korean fabs is being routed to slower greenfield US sites for strategic reasons. The reshoring program is, in this sense, partially causing the duration of the squeeze, not solving it.
The geopolitics that the squeeze now sits inside
A demand-driven commodity squeeze becomes a different kind of problem when the commodity is also a strategic resource. By 2026 the DRAM and HBM markets are clearly in that category, and three policy threads are tangling together.
The first is the China export-controls regime, which has been escalating in stages since 2022. The United States restricts the sale of leading-edge AI accelerators to China and has progressively tightened the rules around what HBM can be shipped where. The HBM-specific restriction arrived with the Bureau of Industry and Security rule of December 2, 2024, which has effectively excluded HBM2E and later from China-bound product. In June 2026 Taiwan moved to broaden its own controls, extending restrictions previously focused on Huawei to all Chinese customers of Taiwan-made AI components. This is a meaningful escalation because CoWoS, the bottleneck on HBM packaging, lives at TSMC. A more comprehensive Taiwan rule choke point further constrains where HBM-bearing accelerators can legally land.
The second is the strategic vulnerability of the supply chain itself. The world’s HBM is made by two Korean companies and packaged by one Taiwanese company. Any cross-strait crisis that disrupts TSMC operations would halt AI accelerator shipments worldwide within weeks. Any North Korean provocation that threatens the Korean memory belt does the same to HBM. There is no plausible second source on the kind of time horizon that matters in a crisis. This concentration is itself a stock-to-flow argument: the production side is geographically as well as economically concentrated, and that concentration is a tail risk that markets are not pricing.
The third is the domestic political response inside the United States, where the AI supremacy framing has taken hold across both parties. Senator Bernie Sanders introduced a bill proposing 50 percent public ownership of US AI companies, with the federal stake funding a $1,000-per-citizen annual dividend. Vice President JD Vance has stated, in interviews from earlier this month, that the Trump administration “likes the idea” of the United States taking equity stakes in every major American AI company, preferring what Vance calls “pre-distribution” to Sanders’ direct-dividend approach. Whether or not any such proposal passes, that two politicians representing opposite ends of the spectrum are converging on US government ownership of AI companies is itself information. It is the kind of policy reflex that surfaces only when an industry has become so important and so strategically constrained that markets are no longer regarded as the right allocator.
You can read these three threads as separate stories, or you can read them together. Read together, they are a textbook account of what happens when a low stock-to-flow commodity meets a strategic-resource framing during a demand wave. Export controls layer on top of restricted production. Geographic concentration multiplies tail risk. Domestic politics reaches for equity stakes because the price signal alone is no longer doing the work governments want it to do.
The squeeze, in other words, is not just an economic event. It is an event that the major powers have decided to treat as strategic. That decision will outlast the price spike.
How long does this last
The natural question is when this resolves and the natural answer is “later than the optimistic forecasts.” Let me sketch the math.
On the supply side, baseline DRAM wafer capacity grows roughly 5 to 7 percent year over year through ordinary fab expansion. HBM capacity is growing faster, perhaps 50 to 80 percent year over year through 2026, but from a small base, and that growth is itself eating wafer capacity that would otherwise have gone to non-HBM products. Net new consumer DRAM supply growth in 2026 is, on most analyst forecasts, very close to zero. SK Hynix has signalled supply will remain constrained through the second half of 2026. None of the new US fabs are in the relief picture. The earliest plausible date for meaningful new supply, from Micron Boise plus the Korean expansions plus modest CoWoS additions, is late 2027.
On the demand side, the projected hyperscaler AI capex still climbs through 2027 on all the consensus forecasts I can find. There is no observable deceleration in training-cluster orders. The major model labs continue to announce new generations on roughly six-to-nine-month cycles. Any individual hyperscaler could blink, but the dynamic is collective: nobody wants to be the first to cut, because each of them is competing for a finite frontier-AI labor pool and a finite training-data advantage. So the demand wave is unlikely to break of its own accord before late 2027 or 2028 at the earliest.
That leaves two demand-side counter-levers worth taking seriously.
The first is quantization. Quantization is what allows large models to fit in less memory by representing each parameter with fewer bits. The default training precision is FP16, at two bytes per parameter. INT8 halves that with almost no quality cost. INT4, the current standard for local inference, halves it again, and a 70-billion-parameter model that would weigh 140 gigabytes in FP16 weighs about 35 gigabytes at INT4. Research has now pushed below 4-bit, with 1.58-bit weight schemes such as BitNet b1.58 producing usable models. Each halving of bit-width roughly halves the memory required for the same weights, but the gains plateau as you approach the floor of one bit per parameter, beyond which a model becomes a calculator. The current consensus floor for high-quality inference sits somewhere between 1.58 and 2 bits.
Since 2022, quantization has bought roughly eight times the memory efficiency of FP16 for inference. That is a real demand-side response and it is the only reason consumer hardware is in the game at all. But it is a one-shot buffer. Once you are at two-bit, there is almost nowhere left to compress. Frontier model sizes meanwhile continue to grow by 5 to 10 times per generation. The arithmetic favours the model side over the quantization side over any horizon longer than a couple of generations.
The second counter-lever is architectural. Mixture-of-experts models like Qwen3.5 122B-A10B and DeepSeek V4 use a large total parameter count but route each token through only a small fraction of those parameters. From an inference standpoint, this offers a way to keep frontier capability while reducing the working memory needed per request. MoE models are still memory-heavy because all the parameters must be loaded somewhere, but they reduce the compute side of inference by an order of magnitude, which makes them more practical on lower-tier hardware. The combination of MoE architecture and aggressive quantization is approximately the best technical answer the demand side has to the squeeze, and the open-weight community has been pushing hard in both directions.
Combine both levers and the practical reading is this. Consumers will keep getting more capability per gigabyte of memory through 2027 and 2028, possibly by another two-times to four-times factor. Frontier model sizes will outpace that. The squeeze on consumer hardware therefore persists in some form through the end of the decade, but its character shifts from “you cannot run anything” to “you cannot run the frontier.” Which is, broadly, where we are today.
Closing reflection
Stock-to-flow is a useful lens because it tells you, before you build a detailed model, who pays and how long it takes for the bill to land.
In the DRAM squeeze of 2025–2027, the question of who pays is now clear. The hyperscalers pay, with margin compression on their AI capex, but they have the cash flow to absorb it. The memory producers profit, with margin expansion that has already shown up in the SK Hynix and Samsung earnings reports. The consumers pay the most surprising part of the bill, because the consumer market is the residual buyer of wafer capacity, and the residual buyer always pays first when supply gets tight. Apple cutting Mac Studio max RAM from 512GB to 96GB in fourteen months is one specific manifestation. Higher PC and phone prices, lower memory ceilings on workstations, and a roughly one-generation lag in what you can run locally are the broader manifestations.
When does it end? The math gives a clearer answer than the headlines do. Production cannot ramp meaningfully before late 2027. Quantization buys a few more gigabytes per dollar but is approaching its physical floor. Therefore the squeeze ends only when the AI demand wave breaks, which on current trajectories does not happen before 2028 and may take longer. Governments are already starting to behave as if it will take much longer than that, which is why nationalization arguments and export-control escalations are showing up in places they would not have shown up two years ago.
It is worth stepping back and noticing how cleanly this whole picture rhymes with the deeper point of the slug-and-Bitcoin essay. In that piece the argument was that high stock-to-flow commodities make good money, because their value is stable against demand shocks and their producers cannot cheat. The DRAM market is the other end of the same axis. It is a low stock-to-flow commodity whose value swings violently against demand, whose producers ride those swings to enormous profits and equally large losses, and whose consumers ride them as a tax. The two essays are arguing the same framework from opposite ends. High S2F protects holders. Low S2F bills consumers. The Mac you might have bought with 256GB last year and cannot buy this year is the bill arriving.
There is a small irony to close on. The wave that ate your laptop RAM is the same wave that, two or three years from now, will produce the AI tools that you would have wanted to run on it. The trick is making it through the squeeze long enough for those tools to arrive and the squeeze to end. The honest market answer, as of June 2026, is: buy as much memory as you can afford right now, because next year you will be paying more for less.
References
- Apple no longer offers M3 Ultra Mac Studio with original highest RAM configuration. 9to5Mac, March 5, 2026. https://9to5mac.com/2026/03/05/apple-no-longer-offers-m3-ultra-mac-studio-with-original-highest-ram-configuration/
- Mac Studio 512GB RAM Option Disappears Amid Global DRAM Shortage. MacRumors, March 5, 2026. https://www.macrumors.com/2026/03/05/mac-studio-no-512gb-ram-upgrade/
- Apple Cuts More Mac Studio and Mac Mini RAM Options as Memory Shortage Worsens. MacRumors, May 5, 2026. https://www.macrumors.com/2026/05/05/apple-mac-studio-mac-mini-ram-cuts/
- Apple quietly axes 128GB Mac Studio amid supply constraints and local AI frenzy. Tom’s Hardware, May 2026. https://www.tomshardware.com/desktops/apple-quietly-axes-128gb-mac-studio-amid-supply-constraints-and-local-ai-frenzy-highest-memory-capacity-reduced-to-96gb-two-months-after-discontinuation-of-512gb-model
- Samsung, SK Reportedly Hike Server DRAM Prices 60-70%; Google, Microsoft in the Queue. TrendForce, January 6, 2026. https://www.trendforce.com/news/2026/01/06/news-samsung-sk-reportedly-hike-server-dram-prices-60-70-google-microsoft-in-the-queue/
- Samsung, SK hynix Reportedly Plan ~20% HBM3E Price Hike for 2026. TrendForce, December 24, 2025. https://www.trendforce.com/news/2025/12/24/news-samsung-sk-hynix-reportedly-plan-20-hbm3e-price-hike-for-2026-as-nvidia-h200-asic-demand-rises/
- DRAM and NAND prices jump as Samsung, SK Hynix and Micron tighten supply. Astute Group, 2026. https://www.astutegroup.com/news/memory-shortages/dram-and-nand-prices-jump-as-samsung-sk-hynix-and-micron-tighten-supply/
- NVIDIA DGX Spark product page (GB10 Grace Blackwell, 1 PFLOPS FP4, 128GB coherent unified memory). NVIDIA Marketplace, 2026. https://marketplace.nvidia.com/
- NVIDIA DGX Spark In-Depth Review: A New Standard for Local AI Inference. LMSYS Org, October 13, 2025. https://www.lmsys.org/blog/2025-10-13-nvidia-dgx-spark/
- Open-Source LLMs Landscape: Qwen, Llama, DeepSeek, Kimi. Codersera, May 2026. https://codersera.com/blog/open-source-llms-landscape-2026/
- A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026. Sebastian Raschka, 2026. https://magazine.sebastianraschka.com/p/a-dream-of-spring-for-open-weight
- Bernie Sanders files bill proposing 50% public ownership of US AI firms; VP Vance says Trump supports giving the American people a stake in AI companies, prefers ‘pre-distribution’ over giving away cash. Tom’s Hardware, June 2026. https://www.tomshardware.com/tech-industry/artificial-intelligence/bernie-sanders-files-bill-proposing-50-percent-public-ownership-of-us-ai-firms-and-giving-out-usd1-000-dividends-vp-vance-says-trump-supports-giving-the-american-people-a-stake-in-ai-companies-prefers-pre-distribution-over-giving-away-cash
- Taiwan Reportedly Mulls Tighter AI Chip Export Rules on China Beyond Huawei. TrendForce, June 10, 2026. https://www.trendforce.com/news/2026/06/10/news-taiwan-reportedly-mulls-tighter-ai-chip-export-rules-on-china-beyond-huawei-raising-risks-for-server-makers-like-foxconn/
- Saifedean Ammous (2018). The Bitcoin Standard: The Decentralized Alternative to Central Banking. Wiley. Source for the stock-to-flow framing applied to monetary commodities.
- U.S. CHIPS and Science Act, Department of Commerce announcements on fab subsidies and recipient timelines: Intel Ohio, TSMC Arizona, Samsung Taylor, Micron Boise and Clay, SK Hynix West Lafayette. https://www.commerce.gov/